ok I think I found something even better.
To generate those bumps, simpleFOC implements Space Vector pwm
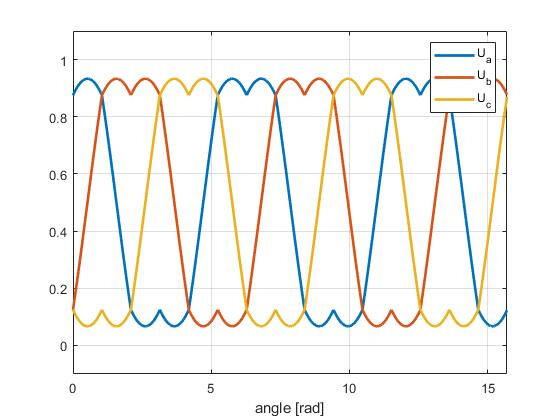
But you can also just apply a midpoint clamp to the actual simpleFOC sinusoidal implementation after the Clarke transform.
Replacing this here:
center = driver->voltage_limit/2;
// Clarke transform
Ua = Ualpha + center;
Ub = -0.5f * Ualpha + _SQRT3_2 * Ubeta + center;
Uc = -0.5f * Ualpha - _SQRT3_2 * Ubeta + center;
By this:
center = driver->voltage_limit/2;
// Clarke transform
Ua = Ualpha;
Ub = -0.5f * Ualpha + _SQRT3_2 * Ubeta;
Uc = -0.5f * Ualpha - _SQRT3_2 * Ubeta;
if (svpwm){
float Umin = min(Ua, min(Ub, Uc));
float Umax = max(Ua, max(Ub, Uc));
center -= (Umax+Umin) / 2;
}
Ua += center;
Ub += center;
Uc += center;
Tada, it should be nearly as fast as sinePWM, no atan2 anymore.